
「ボイスボットって、結局あまり使えないよね」
——そんな声を、コールセンターの現場で耳にすることは少なくありません。
たとえば、音声認識の精度が低く、うまく会話が成り立たない。結局オペレータにつながるまでの時間が長くなり、むしろ非効率になってしまう。そんな経験、ありませんか?
実際、大手SNSのボイスボットを導入している企業の担当者からは、「AI音声が応答はしてくれるけれど、すぐにオペレータに引き継がれてしまって、実質使いものにならない」といった声もあります。
原因はさまざまですが、よくあるのが「顧客のテレビ音声がうるさい」「スマートフォンのマイク性能が低い」といった、外部要因による音声認識の失敗です。
しかし、こうした「使えない」という評価は、必ずしもボイスボット自体の限界ではありません。実は、多くの課題は「音声認識の精度が低いこと」によって生まれているのです。

なぜ、ボイスボットは「使えない」と思われるのか?

ボイスボットに対してネガティブな印象を抱く理由の多くは、認識精度の低さに起因しています。
たとえば以下のような課題がよくあります。
- 背景の雑音や話者の滑舌の影響で、うまく聞き取れない
- 「Q」と「9」、「4(し)」と「7(しち)」といった日本語特有の発音が誤認される
- 会話における文脈が理解できないため、単語の意味を取り違える
実際、従来のSTT(Speech to Text:音声認識技術)は、「聞こえた音」をそのまま文字に変換するアプローチが主流でした。簡単にいうと「音ベース」のSTTです。この方法では、発音が曖昧だったり早口だったりすると、正しく認識できません。
しかし、AIによる音声認識技術は一歩進んでいます。音声をただの「音」としてではなく、「文脈」の中で理解しようとするアプローチです。本当に使えるボイスボットにはこの「文脈ベース」のSTTが必要です。
では実際に「音ベース」と「文脈ベース」のSTTでは、認識結果にどんな違いがあるのか見てみましょう。
比較例1:「カード」 vs 「カート」
- お客さまの発話:「クレジットカードでお願いします」
- 「音ベース」のSTT:「クレジットカートでお願いします」
- 「文脈ベース」のSTT:決済に関する文脈から“カード”と認識
比較例2:「佐藤」 vs 「砂糖」
- オペレータの発話:「佐藤と申します」
- 「音ベース」のSTT:「砂糖と申します」
- 「文脈ベース」のSTT:文脈から「苗字」だと分かるため「佐藤」に補正
このように、文脈まで加味することで、より実践的な音声認識が可能になるのです。
「文脈ベース」のSTTは短文が苦手?
「文脈ベースの音声認識では、短い単語の認識が苦手なのではないか」とお感じになることはありませんか。確かにそうです。
実際のシチュエーションで考えてみましょう。
AIが「お繋ぎする部署名を教えてください」とアナウンスした際、お客さまが「総務課をお願いします」と返答されるケースがあります。この返答は単語数が少なく、発話時間もわずか1〜2秒程度と非常に短いものです。これでは「総務課」を正しく聞き取ることが難しくなります。
しかし、弊社が採用している高精度STTエンジン「Namitech(ナミセンス)」には辞書機能が搭載されているため、短い発話であっても認識精度を向上させることができます。
あらかじめ部署名などの短くて間違えやすい単語を辞書に登録しておくことで、短い返答であっても正確に読み取れるようになります。
実際にユーザー様にテストしていただいた結果では、この辞書機能を活用することで認識精度を25%以上向上させることができました。
文脈まで理解するSTT「NamiSense」:正答率93.91%の実力
音声認識ソリューションを提供するNamitech社の文脈ベースのSTTエンジン「NamiSense(ナミセンス)」は、従来のSTTとは異なるアプローチで高い正答率を実現しています。
とくに曖昧な発話や、同音異義語が多い日本語において、その精度の差は顕著です。
「NamiSense」の文字認識率は一般的な環境であれば93.91%です。電車の中といった騒音下でも93.57%です。
※騒音下の平均的な精度は、85%前後と言われています。
さらに同音異義語テストによる比較では、以下のようなCER(文字誤り率)の結果が得られています(※当社調べ):
※文字誤り率(CER)は、システムが予測したテキストと正しいテキストを比較して、どれだけの文字が誤っているかを示す指標です。CERが低いほど、システムが正確にテキストを認識していることを意味します。
| STTエンジン製品名 | CER(文字誤り率) |
|---|---|
| NamiSense | 0.07 |
| 0.11 | |
| Watson | 0.15 |
この結果は、実際のコールセンター現場においても再現されており、従来型のSTTと比べて、実運用においても高い効果を示しています。
「構築が大変」はもう過去の話。ボイスボットを簡単に作れる「Bright Pattern」

ボイスボットの導入には「構築の難しさ」もつきものでした。とくに、IT人材が限られている企業にとっては、大きな障壁だったかもしれません。
しかし、AIコンタクトセンターシステム「Bright Pattern(ブライトパターン)」であれば、そうした課題は解消されます。
- 音声AIエージェント機能:音声AIエージェント機能でボイスボットを簡単構築
- コーディング不要:テンプレートから簡単にシナリオを構築可能
- 直感的なUI:非エンジニアでもすぐに使える操作画面
コールセンターの管理者が自ら操作し、すぐに運用開始できるため、構築にかかる時間とコストを大幅に削減できます。

音声AIエージェントならシナリオ作成が楽になる!
従来のボイスボット運用では、さまざまな条件や状況に対応するため、数多くのシナリオを事前に作成する必要がありました。お客さまの問い合わせパターンを想定し、それぞれに適したフローを設計する作業は、非常に手間がかかるものでした。
しかし、「Bright Pattern」の音声AIエージェントを活用すれば、シナリオ数を大幅に削減することができます。基本的なプロンプト設定をメインに行うだけで、あとはAIが状況を判断して適切に聞き取りを進めてくれるのです。
以下の画像は、「Bright Pattern」で構築する音声AIエージェントの設定画面です。航空機のチケット予約をするために必要な情報をヒアリングするAIエージェントとなっています。
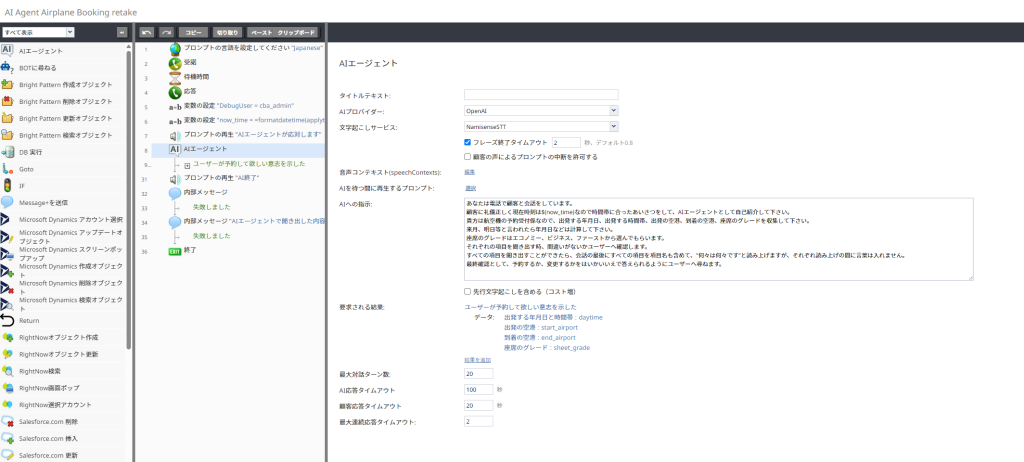
設定したプロンプトに沿って、AIボイスボットがチケット予約に必要な情報を聞き取りしてくれます。非常に構築が簡単です。
これまで数千ものステップを細かく設定しなければならなかったボット運用が、わずか数個の設定だけで運用をスタートできるようになります。設定工数の大幅な削減により、より効率的なボイスボット運用が実現できるのです。

PBXはそのままでもOK。柔軟に選べる「2つの導入パターン」

ボイスボットの導入にあたっては、1)コンタクトセンターシステム「Bright Pattern」を活用するパターンと、2)既存のPBX(電話交換機)を活かせる柔軟なパターンが用意されています。
パターン1:PBXを入れ替え可能
製品の組み合わせ例:高精度STTエンジン「NamiSense」 × コンタクトセンターシステム「Bright Pattern」
特徴:高精度かつ構築しやすいフルパッケージ導入
パターン2:PBXは既存のまま活用
製品の組み合わせ例:高精度STTエンジン「NamiSense」 × AIプラットフォーム「GIDR.ai」 × 既存PBX
特徴:既存環境を活かした段階的な導入が可能
どちらのパターンでも、現場の運用負荷を最小限に抑えながら、ボイスボットの効果を最大化できます。
「認識精度」の向上は、売上向上へつながる
音声の認識精度が向上することで、コールセンター業務の効率化だけでなく、売り上げ向上へ大きく貢献できるようになります。
既存顧客のCX向上
よくある問い合わせへの対応をボイスボットに任せることで、オペレータの稼働を抑えつつ、顧客の待ち時間を短縮できます。その結果、機会損失が減り、顧客満足度(CS)や顧客体験(CX)の向上へとつながっていきます。
新規顧客の獲得
問い合わせへの即時対応は、企業への信頼感を高めます。「すぐに対応してもらえた」という印象は、購買意欲の向上にも直結します。
VOC(顧客の声)を活かしたマーケティング
高精度な音声認識により、文脈に沿った正確なデータ収集が可能になります。顧客のニーズや課題をリアルタイムで把握し、製品・サービス改善に活かせるのです。
「ボイスボット=使えない」は、今日から変えよう

「ボイスボットは使えない」。そう思い込んでいた方も、今がその前提を見直すときかもしれません。
弊社では、以下のサービスを提供しています。
- 文脈を理解する高精度STTエンジン「NamiSense」
- 簡単に構築できる音声AIエージェント搭載「Bright Pattern」
- 既存のPBXもそのまま使える柔軟なボイスボット導入パターン
これらを組み合わせれば、今日から「使えるボイスボット」を業務に取り入れていくことが可能です。
業務効率化だけでなく、顧客満足度や売上にも直結するボイスボットの実力を、ぜひご確認ください。まずはお気軽にご相談ください。
